tl;dr A large-scale, multi-view tennis video dataset with 11M+ frames and novel human pose estimation evaluation framework.
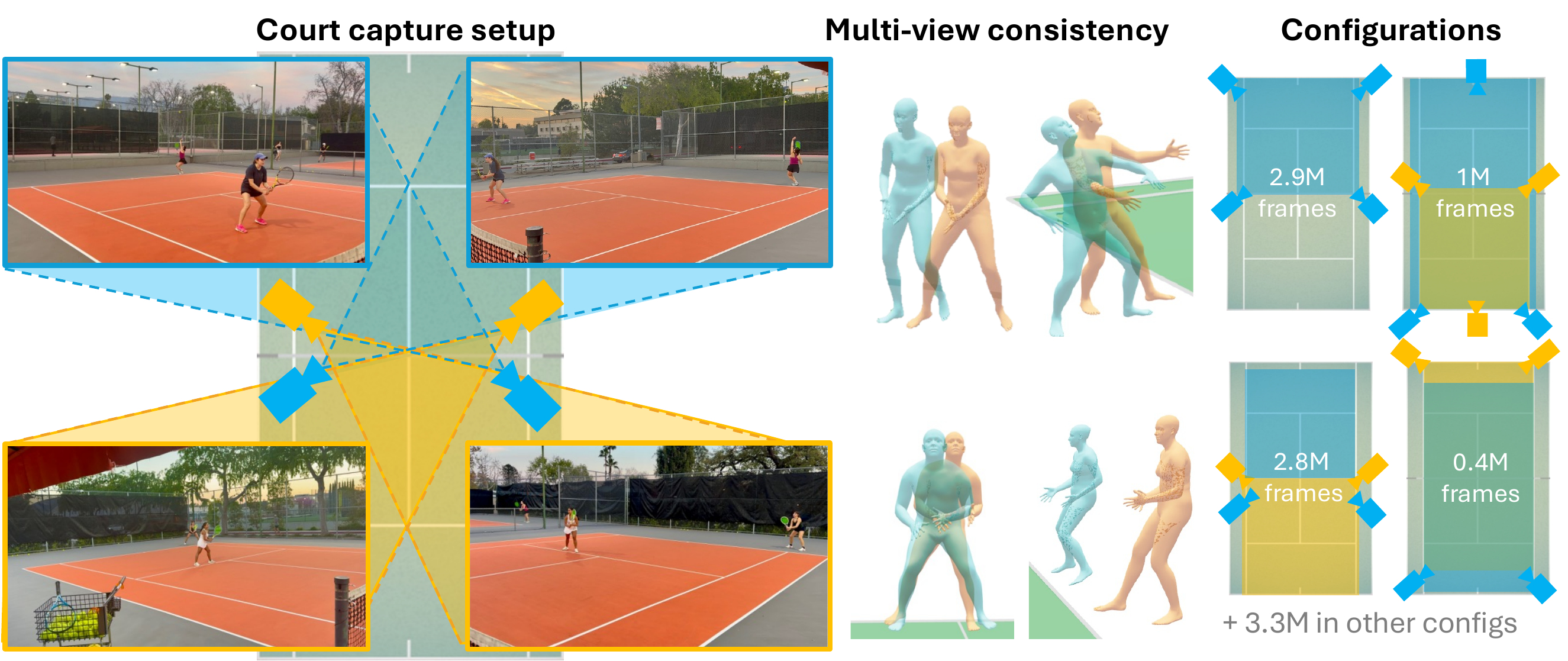
The Caltech Tennis Dataset (CalTennis) is a large-scale video benchmark for evaluating monocular-to-3D pose estimation in the wild. CalTennis comprises over 11 million frames (51 hours) of tennis practice and match play from 40 players, captured with 2–6 synchronized cameras at 60 Hz. It is 10× larger than existing in-the-wild human motion video datasets and 3× larger than existing MOCAP-ground-truthed datasets, and it is the first large-scale benchmark to provide synchronized multi-view recordings of expert athletic motion. The multi-view setup enables inexpensive, label-free evaluation of monocular-to-3D pose estimation algorithms. We describe a simple, standardized protocol that enables data collection without specialized equipment or expertise, along with fully automated video calibration and synchronization. Benchmarking state-of-the-art monocular-to-3D pose methods on CalTennis, we find that while 3D joint angle recovery is now quite accurate, all models struggle to estimate depth and foot contact consistently. We further propose two novel performance metrics — footwork and stability — as well as qualitatively study body shape inconsistency. These metrics expose previously underexplored failure modes and point to concrete opportunities for improvement in pose estimation and action analysis.
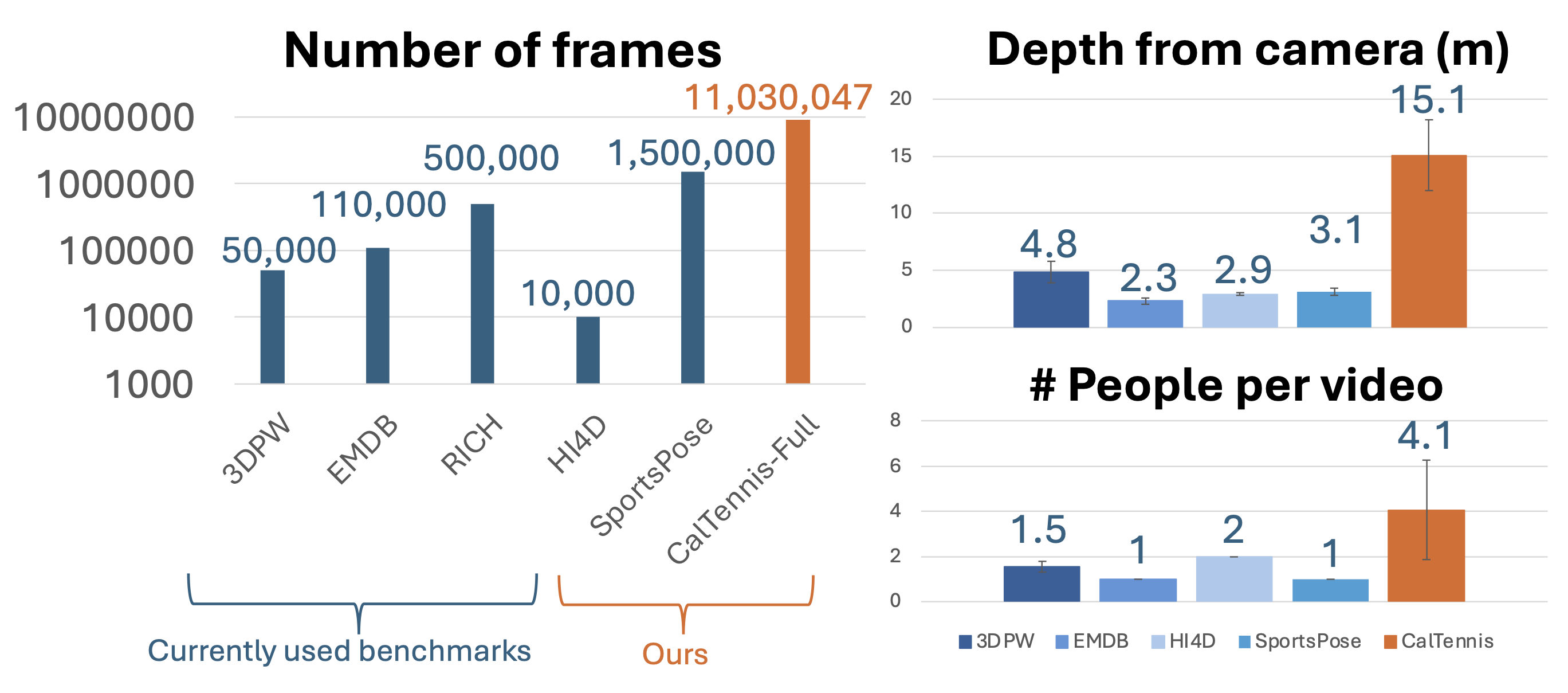
The Caltech Tennis Dataset (CalTennis) is the first benchmark to use multi-view, real-world recordings of skilled human motion, capturing data underrepresented in existing pose datasets and more representative of downstream motion-reconstruction applications. It has significantly more depth variability and pose space coverage. Despite containing 10x more frames than other real-world benchmarks, it is also signifcantly cheaper than current MOCAP and real-world benchmark, requiring only every-day phones mounted on tripods.
| Multi-View? | Real-World? | Num Frames (M) | Avg. Seq Len (s) | Depth Range (m) | Pose Space Coverage | Hardware Cost | |
|---|---|---|---|---|---|---|---|
| 3DPW | ✕ | ✓ | 0.05 | 45 | 3.1–7.4 | 58% | $21k |
| EMDB | ✕ | ✓ | 0.11 | 42 | 1.9–2.7 | 60% | $31k |
| RICH | ✓ | ✓ | 0.54 | 127 | 4.2–4.7 | 62% | $100k |
| Human3.6M | ✓ | ✕ | 1.47 | 340 | 4.5–5.8 | 89% | $150k |
| CalTennis (Ours) | ✓ | ✓ | 11.03 | 3365 | 13.4–16.7 | 85% | $2k |
To evaluate monocular pose estimators without ground-truth labels, we lift pose predictions from each camera into a shared global space-time reference frame:
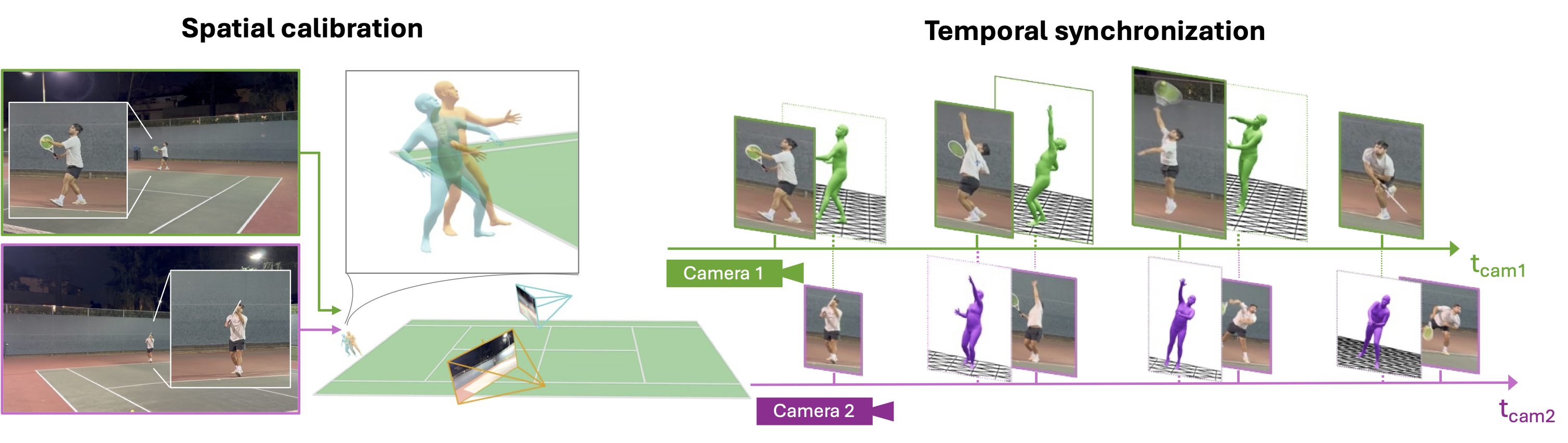
CalTennis uses multi-view consistency as a label-free proxy for reconstruction error: a correct prediction must agree across views, and inter-view disagreement lower-bounds each model's true error. In addition to standard metrics (MPJPE, PA-MPJPE, PVE), we introduce four metrics that expose failure modes invisible to existing benchmarks.
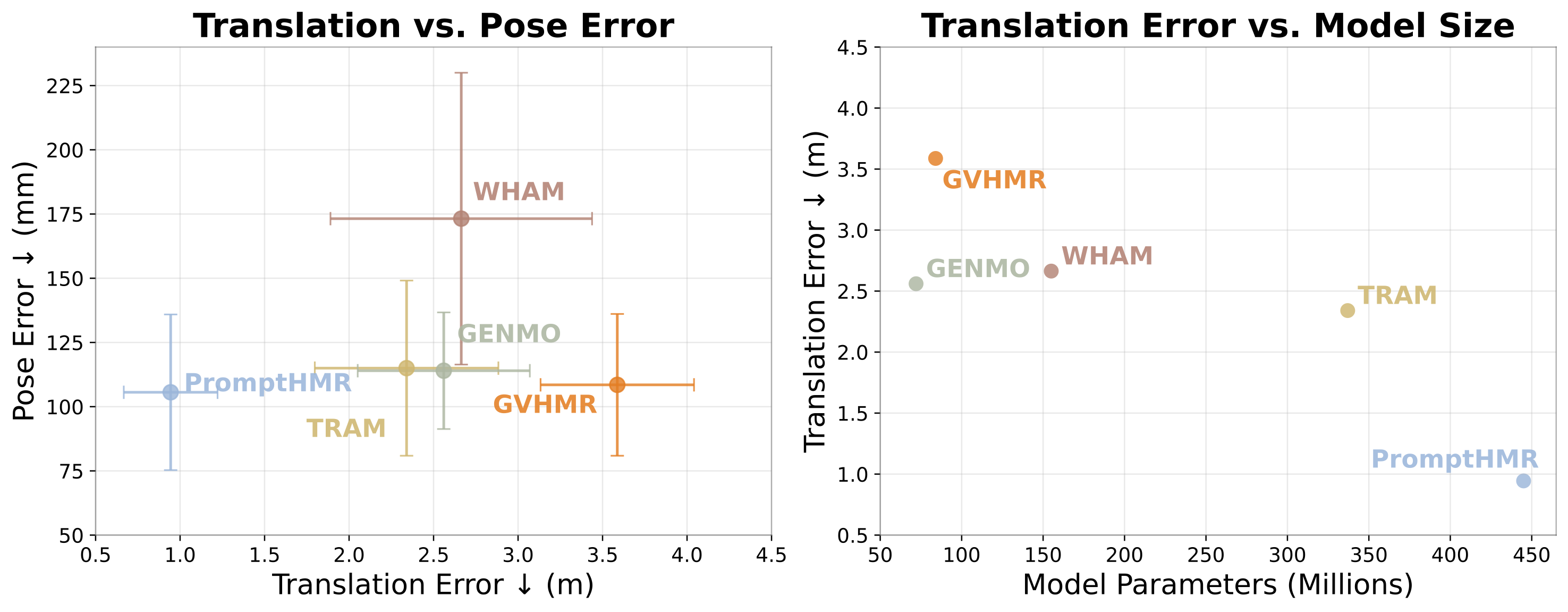
We benchmark five state-of-the-art monocular 3D pose estimators on CalTennis: PromptHMR, WHAM, GVHMR, TRAM, and GENMO. No single model dominates across all dimensions. PromptHMR achieves the most consistent translation and joint-position estimates; WHAM excels at foot velocity consistency thanks to its ground-contact refinement step; GENMO is most consistent on foot height and stability. Across all models, performance on CalTennis is substantially worse than on existing benchmarks, reflecting the challenges of large depth range, fast athletic motion, and unscripted behavior.
We find that all models struggle with making consistent translation estimates, with average error ranging from 0.9m - 3.6m, with 75% of translation errors within a 1m window. As the poses contained in CalTennis span greater distances, pixel-level errors in pose estimates can result in more severe mistakes in translation estimates, an effect that is not obvious from current benchmarks. Qualitatively, we find that this results in a "pose drifting" effect, or oscillations in translation estimates along each camera's depth axis. Models are much more consistent when it comes to pose estimates, with about 11cm error between multi-view poses across all models. This suggests that these models are more ready for downstream applications involving pose estimates alone, rather than those dependent on accurate 3D identification of people in the scene.
| Translation (mm)↓ | Pose (mm)↓ | MPJPE (mm)↓ | PA-MPJPE (mm)↓ | Foot-Vel (m/s)↓ | Foot-Height (mm)↓ | Stability (mm)↓ | |
|---|---|---|---|---|---|---|---|
| PromptHMR | 942 | 105 | 1,785 | 84 | 3.23 | 70 | 25 |
| WHAM | 2,664 | 106 | 2,675 | 119 | 0.72 | 150 | 44 |
| GVHMR | 3,587 | 109 | 1,066 | 88 | 2.49 | 60 | 21 |
| TRAM | 2,340 | 115 | 958 | 91 | 6.65 | 80 | 33 |
| GENMO | 2,560 | 110 | 1,020 | 91 | 4.40 | 60 | 16 |
We find that the most performant model depends on the metric and hardware limitations of the appplication. PromptHMR has the lowest translation inconsistency but also also the heaviest, while WHAM, which is second lowest, is also second lightest. These results highlight the trade-offs between static pose accuracy and temporal/physical consistency
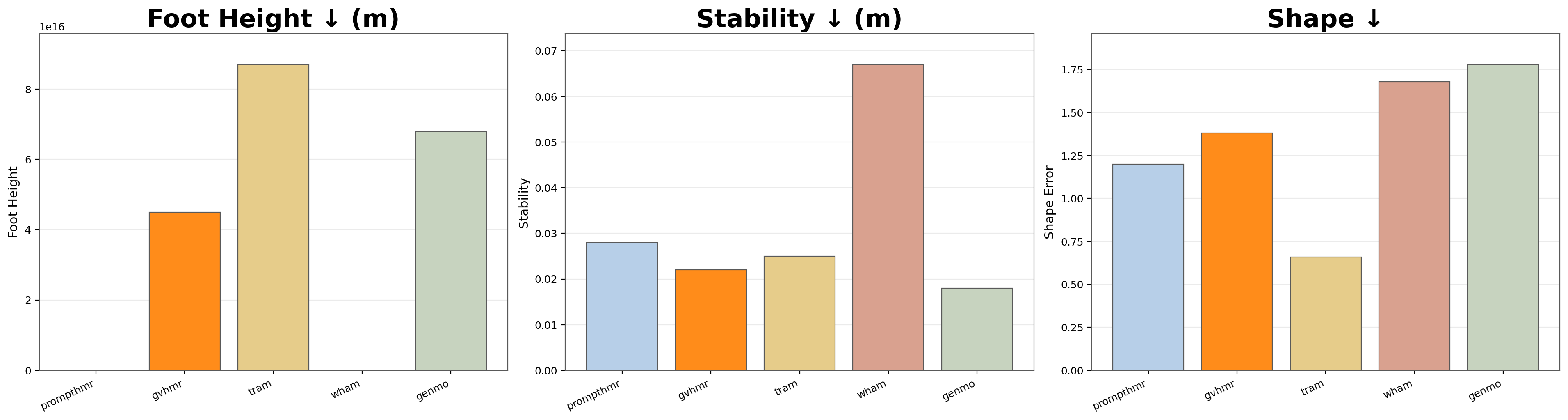
We also compare the consistency of different models along foot skating, stability, and shape estimates. In addition to there being no best model across the board, the relative ordering of model performance for each metric changes as well.
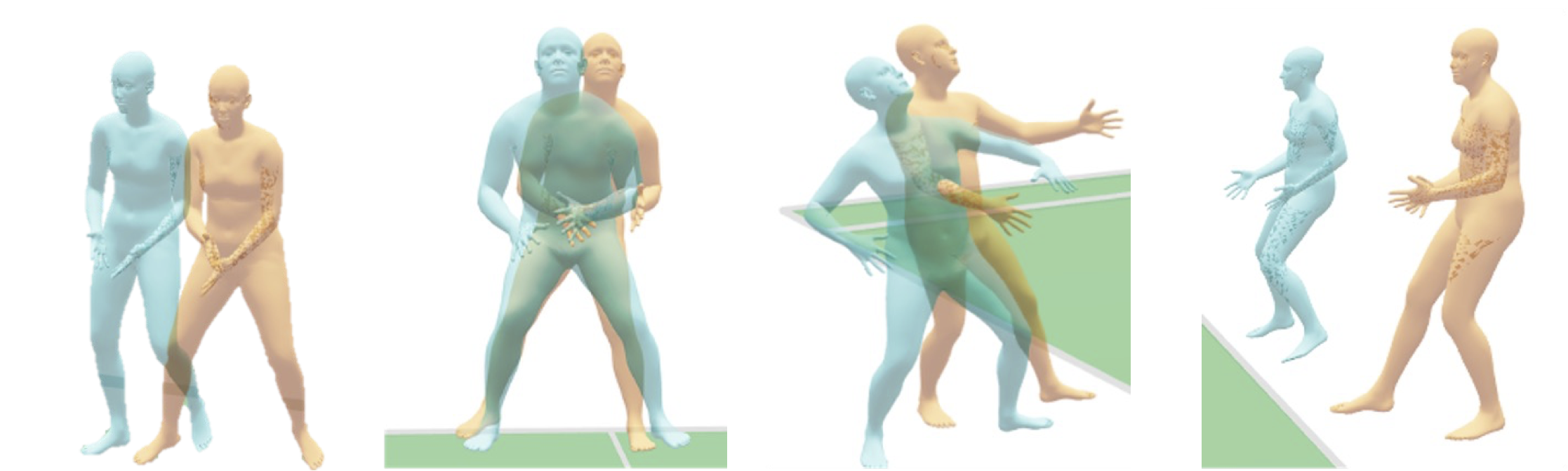
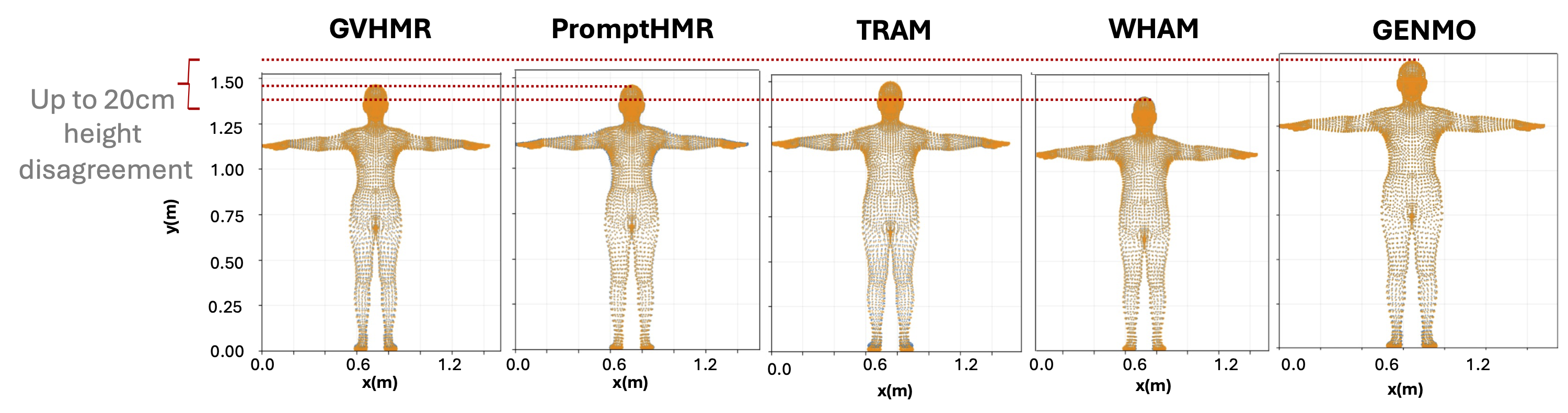
An often-overlooked failure mode is shape inconsistency: the same person's estimated height, weight, and body proportions (SMPL-X β parameters) vary significantly across camera views and across models. All five evaluated models produce inconsistent shape predictions, with up to 20 cm of height disagreement across views. PromptHMR achieves the most consistent multi-view shape reconstruction, likely because it conditions on 2D bounding boxes and keypoints. Models that produce consistent trajectories typically predict shape parameters once per video from the first frame, which is insufficient for accurate biomechanical analysis. Our findings motivate a more nuanced, video-level approach to shape prediction.
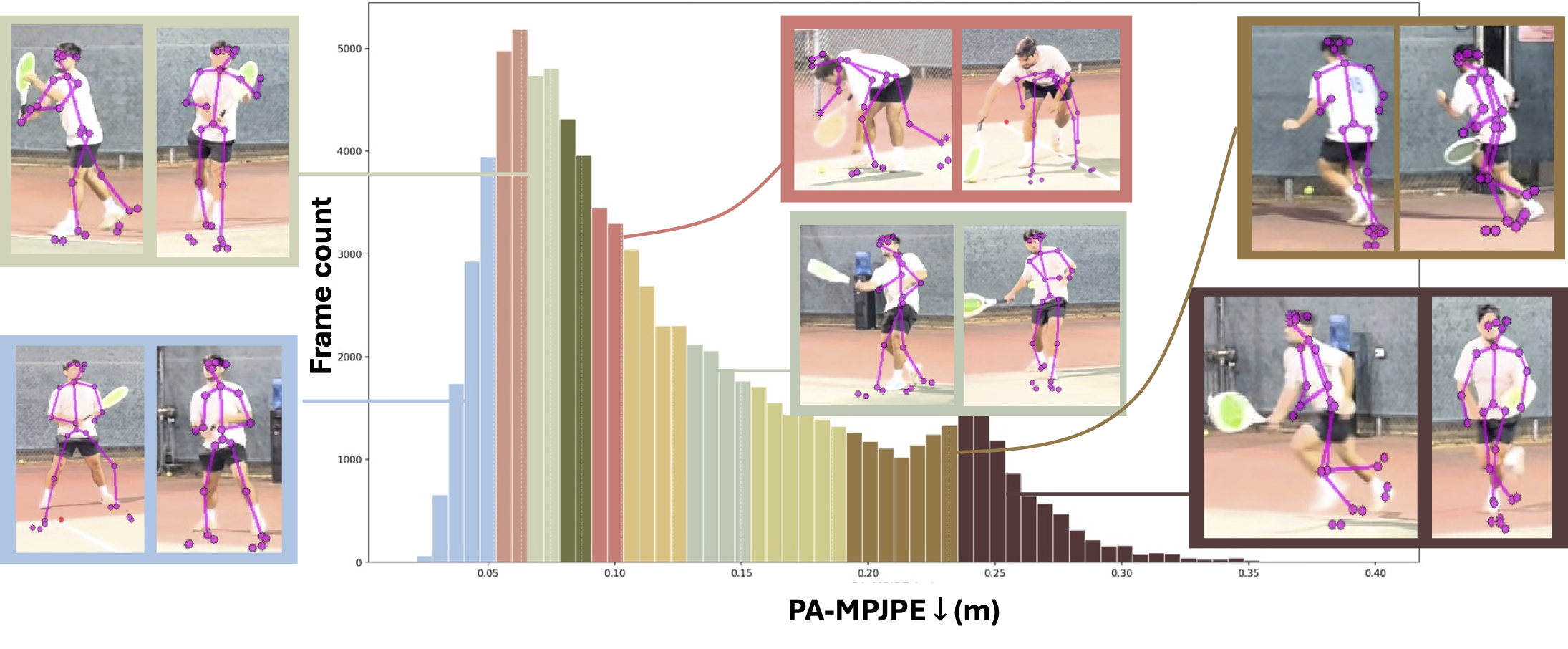
Model failure modes become more clear when we project pose estimates from one camera view onto the other to visualize cross-view inconsistency. Low-disagreement frames correspond to stationary, “neutral” poses equally visible from both cameras. High-disagreement frames occur on distant or dynamic poses with partial occlusion — particularly at feet and hands during strokes and footwork.
No single model is best. Different models excel at different aspects: PromptHMR leads on translation and joint-position metrics but has the largest per-video variance; WHAM excels at foot skating and pose drift at the cost of translation accuracy; GENMO is the most internally consistent across views. The relative model ordering changes with each metric.
Three quantities remain unreliable across every model we tested: absolute distance and depth, ground-contact detection, and body shape (limb lengths, height, proportions). These are exactly the quantities that clinical biomechanical analysis, force and balance estimation, fine-grained sports analytics, pedestrian intent prediction, and forensic stride-length measurement most directly depend on.
@inproceedings{caltennis2026,
author = {Demler, Ilona and Xie, Xinran and Werner, Blake and Szczuka, Anna and Perona, Pietro},
title = {CalTennis: Large Multi-View Tennis Video Dataset and Benchmark of Monocular-to-3D Pose Estimation},
booktitle = {Under Review},
year = {2026},
}