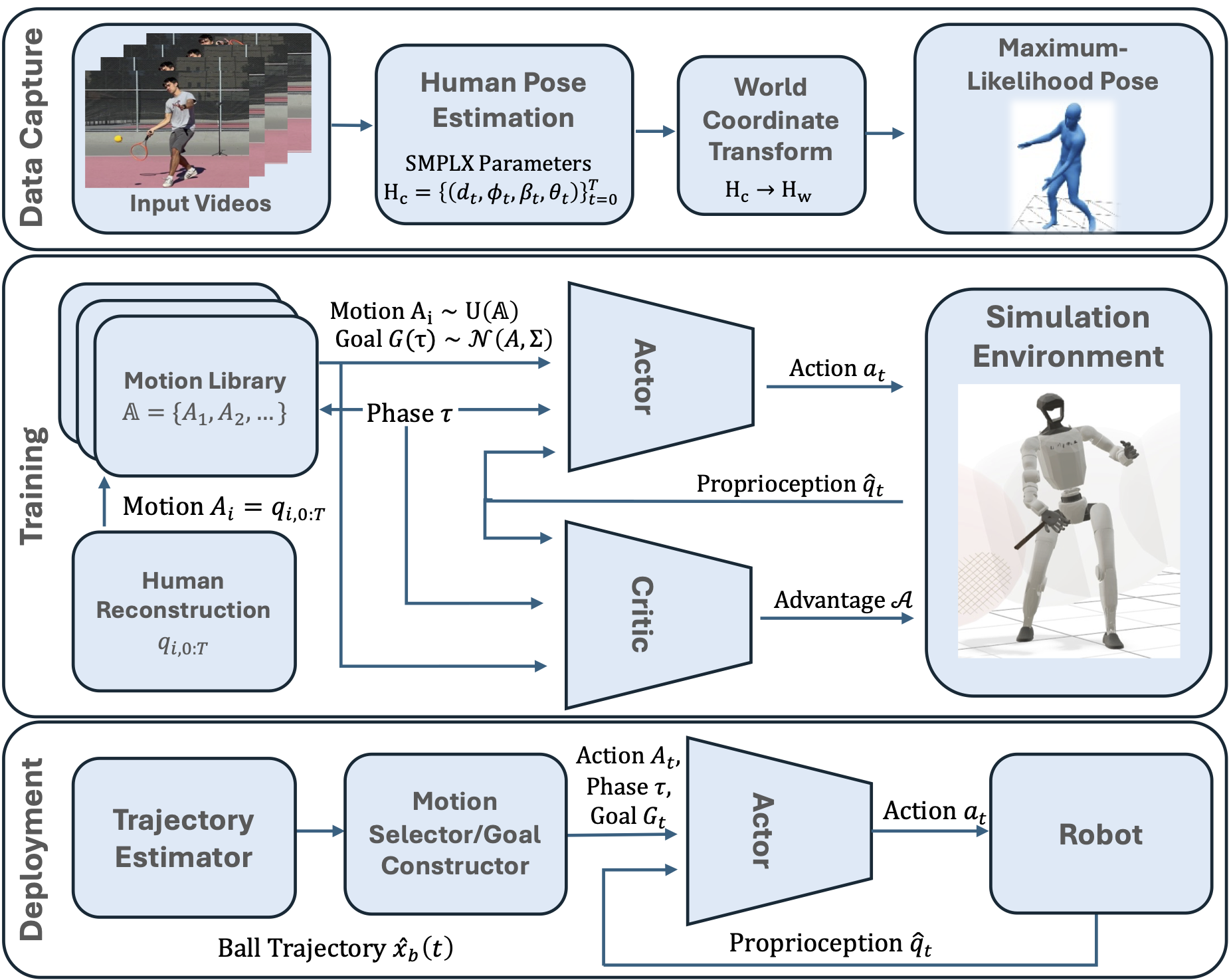
Method
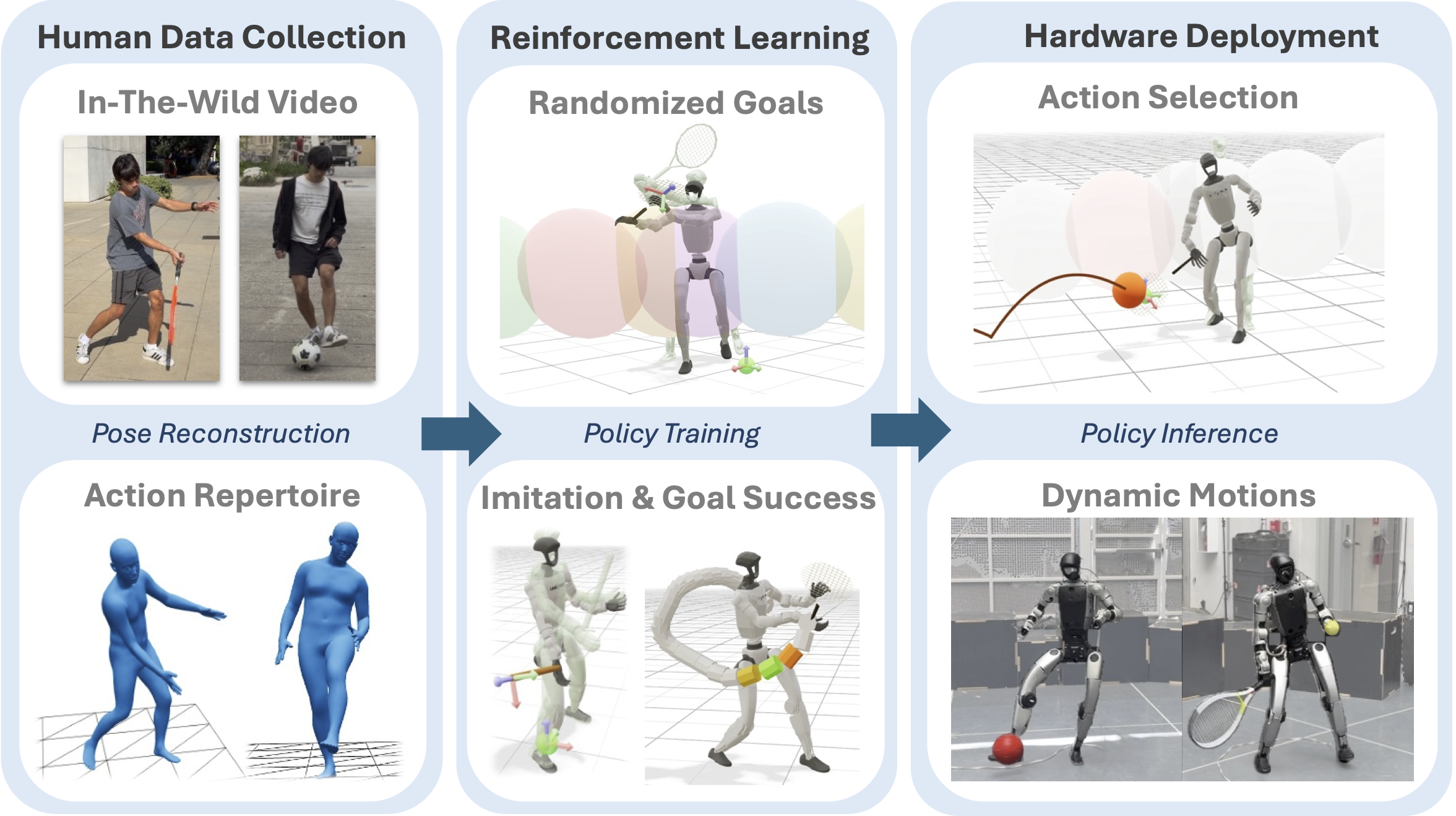
TaskNPoint is a real-to-sim-to-real pipeline with four stages. (1) Human Pose Reconstruction. We collect monocular (or multi-view) video of a human coach demonstrating each skill and recover 3D SMPL-X body pose estimates using PromptHMR. For in-the-wild multi-view footage we fuse per-camera estimates into a maximum-likelihood consensus pose to suppress depth-axis drift. (2) TaskNPoint Abstraction. We kinematically retarget the human motion to the robot morphology with GMR, then annotate the single contact frame (e.g., racket–ball impact) to extract the nominal 3D target point p*, target velocity ν*, and target orientation n*. This compact goal tuple — one point per skill — is the only task-specific information the policy receives. (3) RL Policy. We train a single goal-conditioned PPO policy in MJlab simulation. Target points are randomized around the nominal during training so a single demonstration generalizes zero-shot to novel goal locations. (4) Deployment. An OptiTrack motion-capture system estimates the incoming object trajectory in real time; a Kalman filter and hybrid dynamics model forward-propagate the trajectory, and the nearest motion class is selected via a Voronoi partition over the workspace.